Comment mon IA locale peut diagnostiquer et résoudre automatiquement mes incidents IT
Dans ce billet de blog, je vais vous montrer qu’il est possible de déployer une IA capable de diagnostiquer vos incidents IT, voire même de déclencher des automatisations pour les résoudre.
Tous les outils présentés ici sont hébergés on-premise et basés sur des solutions gratuites.
Après vous avoir présenté mon homelab dans l’article précédent, je me suis posé une question :
Et si ce même homelab pouvait devenir… intelligent ?
Pas juste puissant. Pas juste rapide.
Mais capable de comprendre ce qui se passe, d’analyser mes incidents, et même de m’aider à les résoudre.
Ce nouvel article est plus “accessible” techniquement que le précédent, et probablement plus passionnant.
Le concept : une IA “on-premise” qui veille sur mon infra
Mon objectif était simple :
Avoir un système de monitoring qui ne se contente pas de m’envoyer des alertes, mais qui me parle, qui déclenche des automatisations.
Qui comprend le contexte.
Et qui me guide dans le diagnostic.
Mais sans dépendre d’un service cloud, d’une API externe...
Tout on-premise, gratuit, et sous mon contrôle.
Voici la stack que j’ai mise en place :
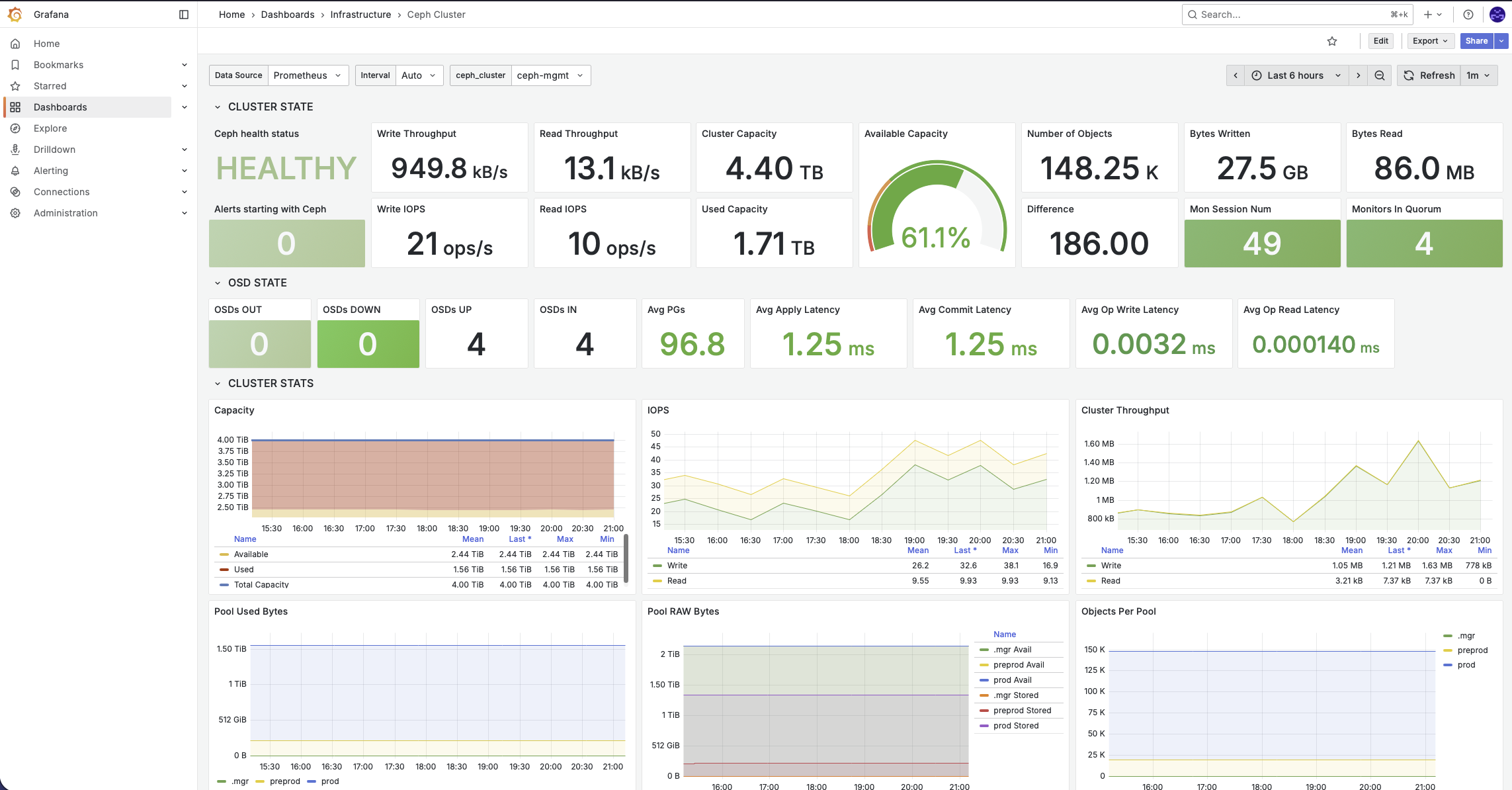
📊 Grafana (grafana.com), l'outil de supervision de référence, il fait la concatenation de tous les metrics (prometheus) et logs (Loki) que j'ai sur mon infrastructure.
Ici un exemple du dashboard correspondant à la supervision de mes cluster Ceph.
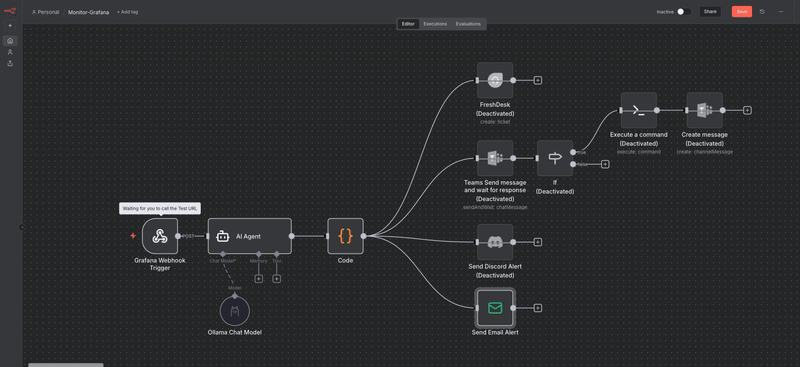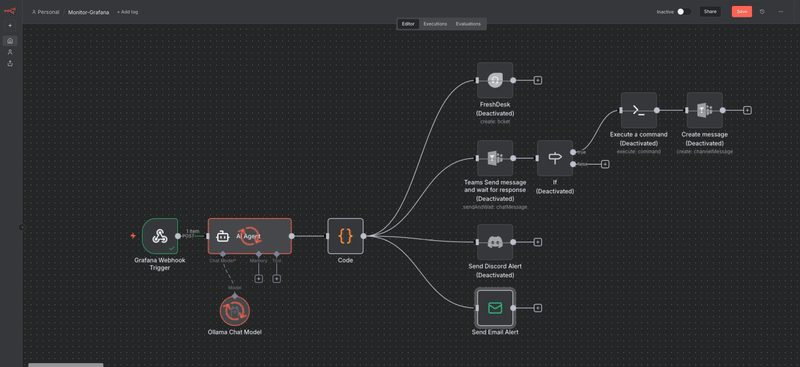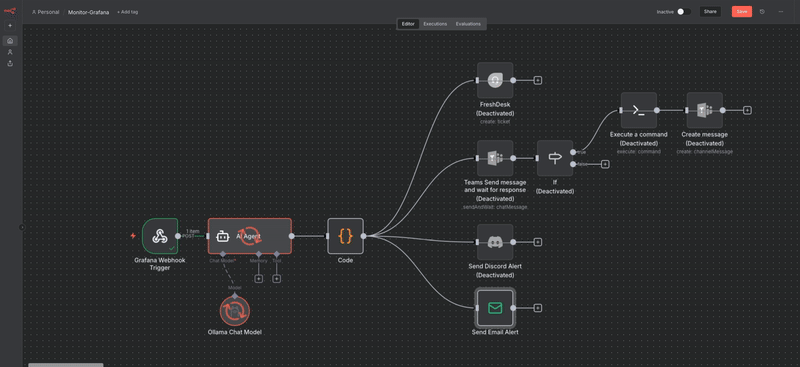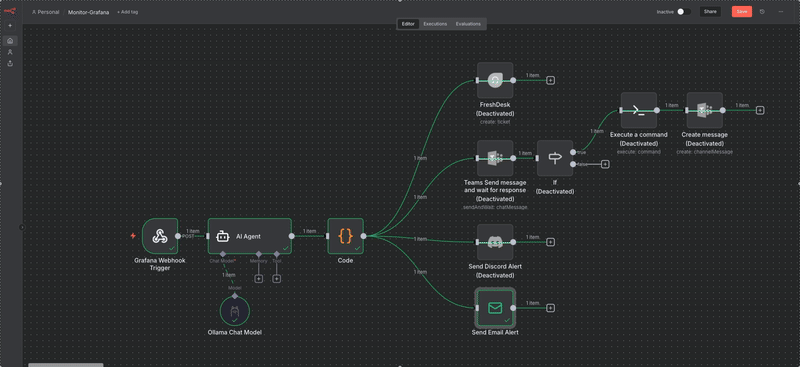
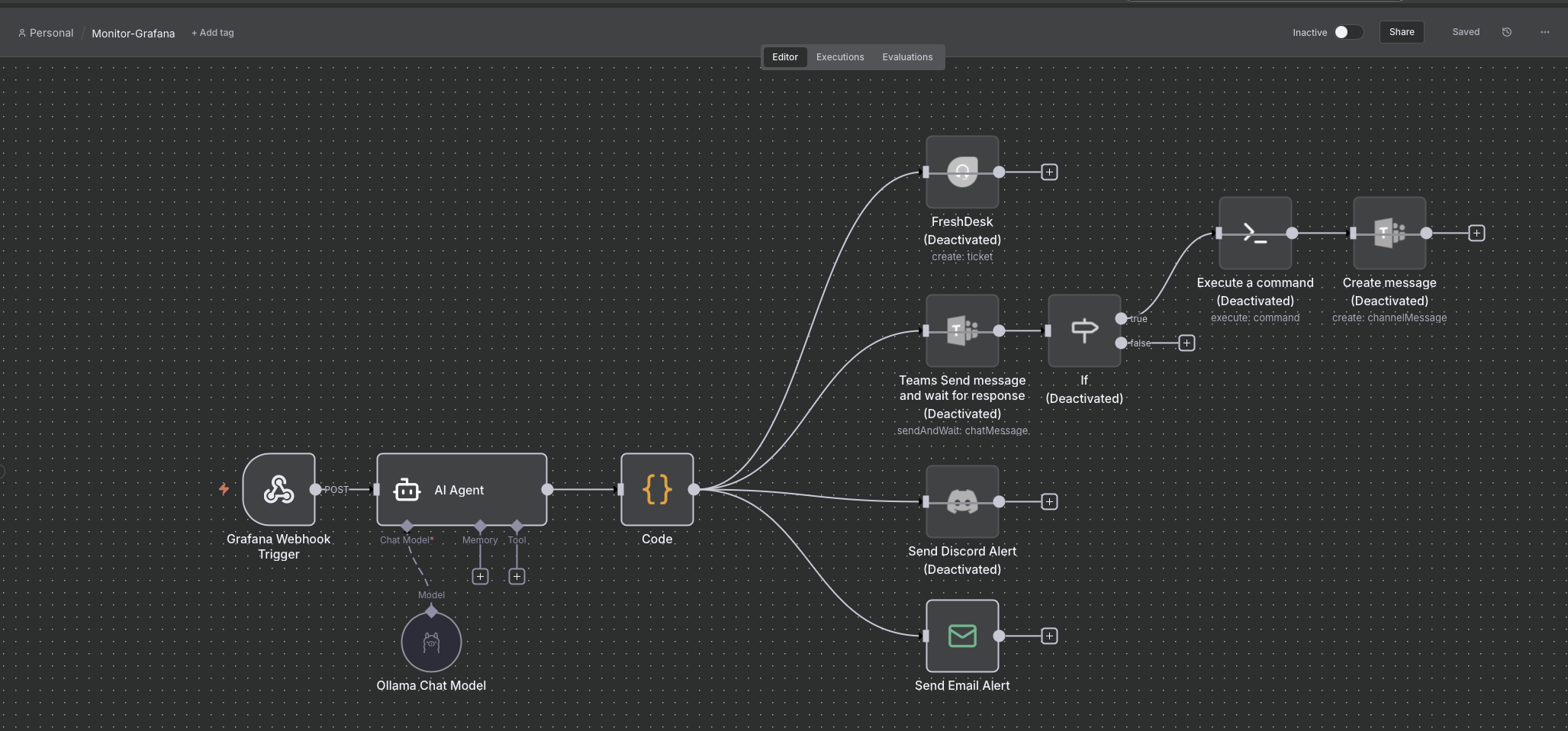
🔄 n8n (n8n.io), un outil d’automatisation open source qui permet de créer facilement des workflows visuels pour connecter et orchestrer différents services, API ou systèmes.
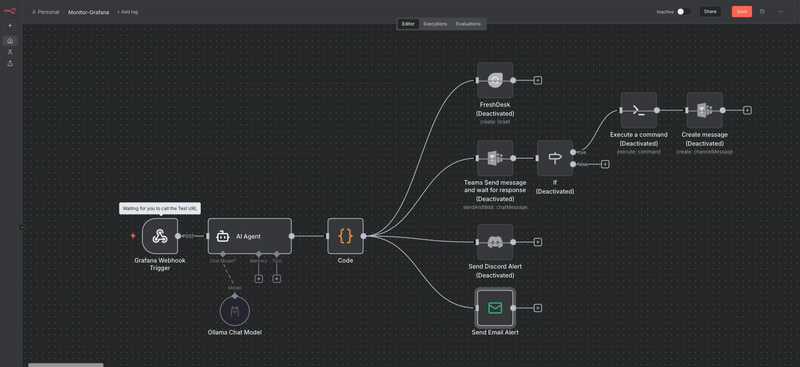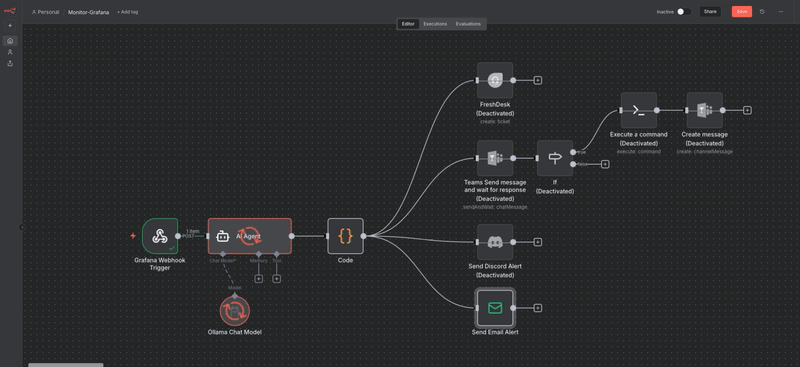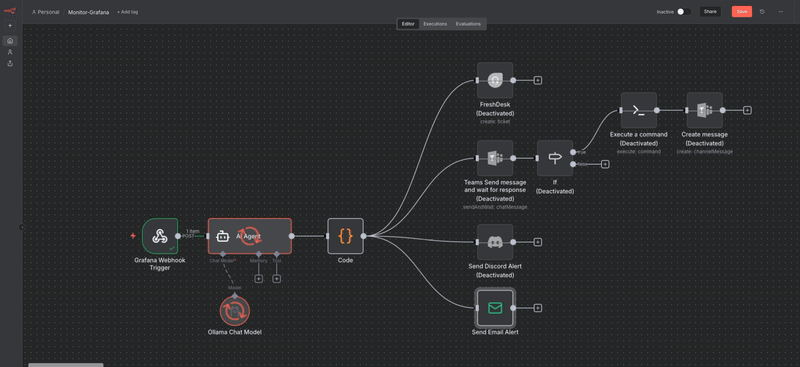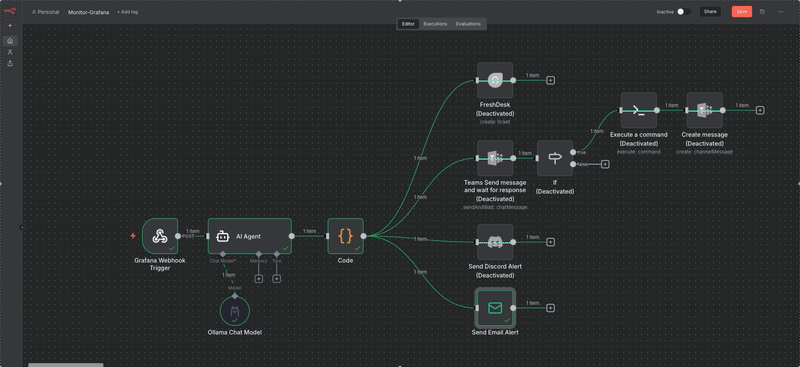
Voici à quoi ressemble la configuration du workflows présenté dans ce billet de blog.
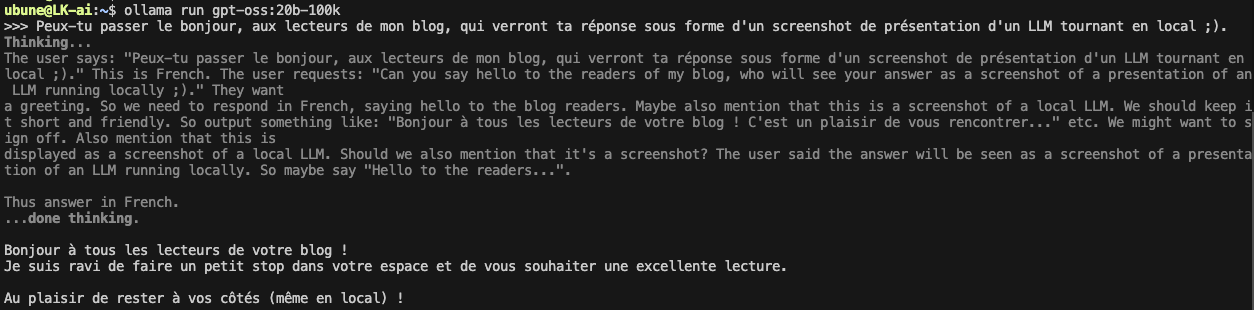
Serveur AI : une VM Ubuntu Server équipée d’une carte graphique Nvidia RTX en passthrough, sur laquelle tourne Ollama, mon moteur d’IA local.
Ollama est une solution open source qui permet d’exécuter localement des modèles de langage (LLM) comme GPT directement sur ta machine, en exploitant les ressources matérielles disponibles (CPU et GPU) pour accélérer le traitement. Elle gère le téléchargement, la configuration et l’exécution des modèles.
🔔 De l’alerte brute au diagnostic intelligent
Avant, quand Grafana m’envoyait une alerte, je recevais un message du genre :
“Server CPU usage critical — 98%”
C’est utile… mais un peu sec.
Ça ne dit pas pourquoi, ni quoi faire.
Et quand tu gères plusieurs serveurs, sites ou environnements, ça devient vite une jungle.
Alors qu'on peut rendre ces alertes plus conversationnelles, plus “intelligentes”.
Étape 1 : Grafana déclenche une alerte enrichie
Chaque alerte contient :
- Le site impacté
- Le type d’équipement
- Le nom du device
- Le constructeur
- Et bien sûr, la description du problème
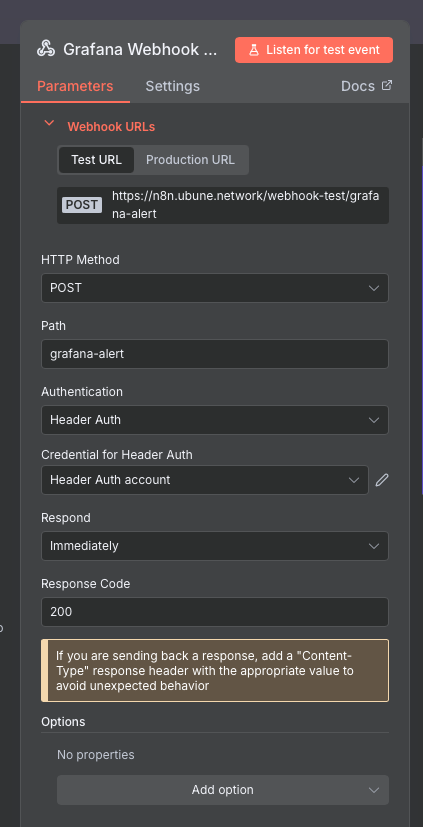
Le tout est envoyé via un Webhook à n8n, ce webhook est donc le déclencheur du scenario N8N.
Un webhook, c'est tout simplement une url dédiée, ici n8n.ubune.network/webhook-test/grafana-alert,
Ce webhook déclenchera le scenario si il reçoit une request http "post" ayant le bon header d'authentification.
Étape 2 : n8n orchestre et parle à l’IA :
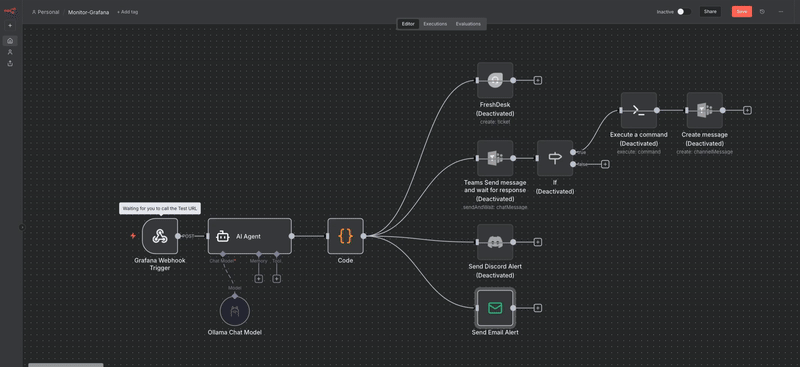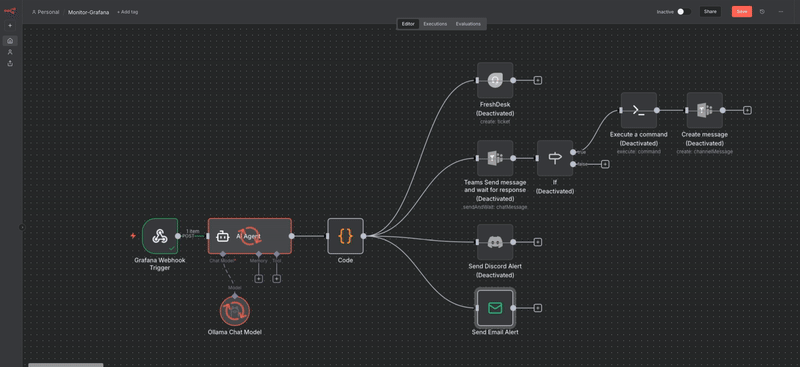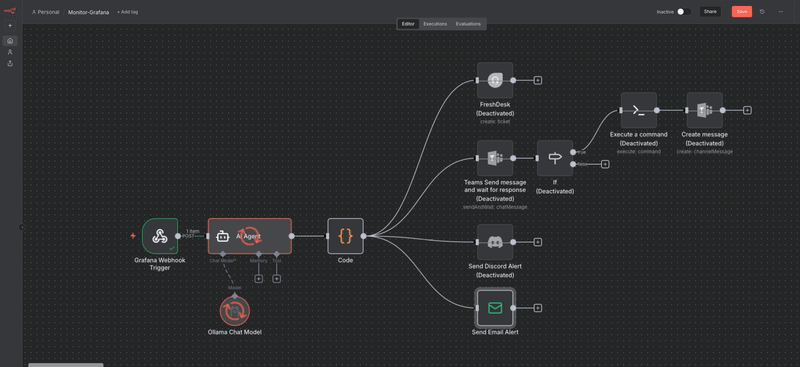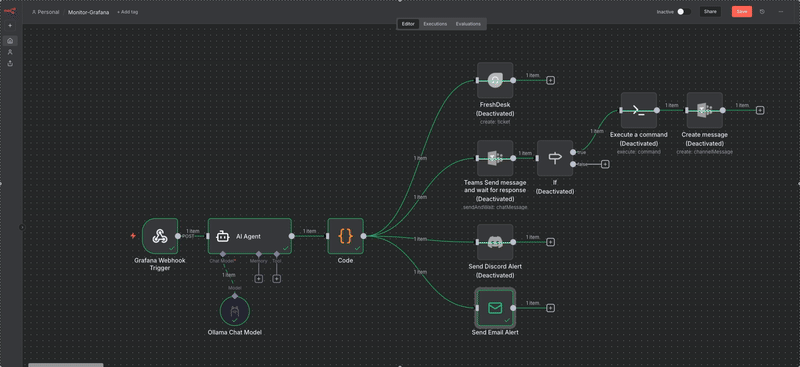
n8n reçoit le webhook, extrait les infos, et les transmet à l'agent IA, configuré pour pointer sur Ollama, mon moteur IA local.
Le modèle que j’utilise actuellement est gpt-oss (version avec 20 milliards de paramètres), tournant intégralement sur mon serveur, ça tourne sur "presque" n'importe quel gpu moderne ayant 16Go de Vram.
Le prompt que j’utilise est le cœur du système.
Le voici :
{
// Nom du modèle exécuté localement via Ollama
"model": "gpt-oss:20b-100k",
"prompt": "You are a senior IT infrastructure engineer assisting a Level 1 technician who received a monitoring alert. Write a one-time diagnostic summary using clean, styled HTML. Your goal is to help the technician understand the issue clearly and act on it.\n\n**Respond only once** using readable HTML with basic inline styling (e.g., <div>, <h2>, <ul>, <code>, <p>, <strong>). Use a friendly, supportive tone — clear and professional.\n\nHere are the alert details:\n- Site: {{ $json.body.From }}\n- Device Name: {{ $json.body['Device Name'] }}\n- Device Type: {{ $json.body['Device Type '] }}\n- Manufacturer: {{ $json.body['Device manufacter'] }}\n- Error: {{ $json.body.Error }}\n\nStructure your HTML like this:\n\n- A header section with site and device info\n- A friendly summary of the issue\n- A probable cause with brief reasoning\n- A clean, styled step-by-step guide for diagnosis\n- Recommended next actions (commands or checks)\n- A final suggestion for prevention or escalation\n\nUse <div style=\"...\"> and light inline styles to visually separate sections. Use <pre><code> for CLI commands. Don't use markdown, don't mention being an AI, and don't include tags like <think>.",
// Sortie complète en une seule fois (pas de streaming)
"stream": false
}
Résultat :
L’IA reçoit en entrée les informations suivantes :
- $json.body.devicename
- $json.body.devicetype
- $json.body.from
- $json.body.Error
Elle est coachée pour se comporter comme un ingénieur IT assistant un technicien de niveau 1, sur un incident correspondant aux éléments JSON reçus.
Son rôle est de me renvoyer un rapport HTML clair, propre et structuré, permettant à un technicien de commencer immédiatement le diagnostic 😉.
La fin du scénario sera tout simplement un e-mail au format html.
Étape 3, démonstration :
Prenons une alerte classique :
Site : Cannes Datacenter CAN02
Device Name : Ubuntu-04
Device Type : Operating System Ubuntu Server
Error : CPU usage over 92% for 10 minutes
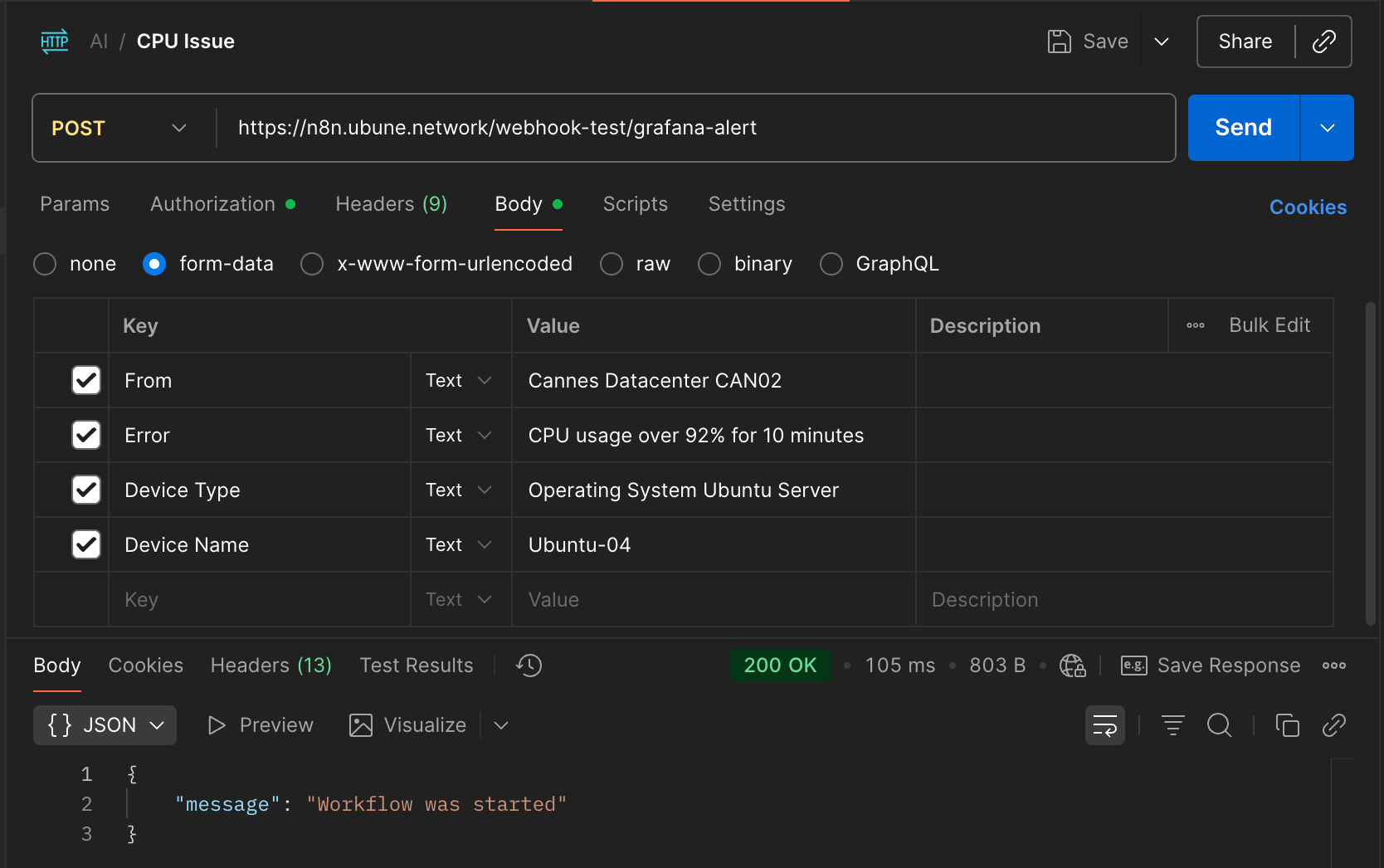
Plutôt que d’attendre qu’un vrai incident se produise pour faire la démonstration, j’ai choisi de simuler l’envoi de l’alerte que Grafana effectuerait en cas de problème, à l’aide de Postman.
J’envoie donc une requête HTTP POST à l’URL suivante :
https://n8n.ubune.network/webhook-test/grafana-alert
Le scenario se déclenche :
Après quelques secondes (temps d'analyse du llm) l'IA me renvoi le mail suivant

Résultat :
- C’est lisible, utile, et immédiatement exploitable.
- Et tout ça sans jamais quitter mon réseau local.
🧩 Pourquoi cette approche marche bien
Quelques avantages à cette architecture :
1. Zéro dépendance cloud
Aucune API externe, aucun coût caché, aucune fuite de données sensibles.
2. Flexibilité totale
Je peux adapter le prompt selon le contexte : supervision, sécurité, réseau, etc.
3. Standardisation
On reçoit une réponse claire, structurée, et exploitable.
4. Évolutivité
Avec n8n, je peux facilement brancher de nouveaux scénarios, comme par exemple :
- L’auto-création de tickets dans un outil ITSM,
- L’envoi d’un résumé d’incident via Teams,
- L’envoi d’un message Teams interactif en attente d’une validation (par exemple avant l’exécution d’un script).
Tous ces scénarios peuvent bien sûr être adaptés selon le jour et l’heure de l’incident afin de, par exemple, déclencher un workflow différent la nuit ou le week-end.
🔭 Et la suite ?
Ce projet n’est qu’un début.
L’étape suivante : rendre l’agent plus “proactif”.
Je travaille actuellement sur :
- La corrélation automatique d’incidents.
- L’analyse contextuelle dans le temps (ex : “cette VM a déjà eu 3 alertes CPU en 24h”)
- Et peut-être… un assistant vocal local pour interagir directement avec mon infra (supervision, visu de logs etc).
🧩 Conclusion
Ce projet est la preuve qu’on peut construire, avec des outils open source et un peu d’imagination, une IA capable d’assister un ingénieur IT au quotidien.
Juste un bon prompt, quelques automatisations bien pensées, et un peu de passion. 🔥